5 min read
Understanding “LLM Evals”!
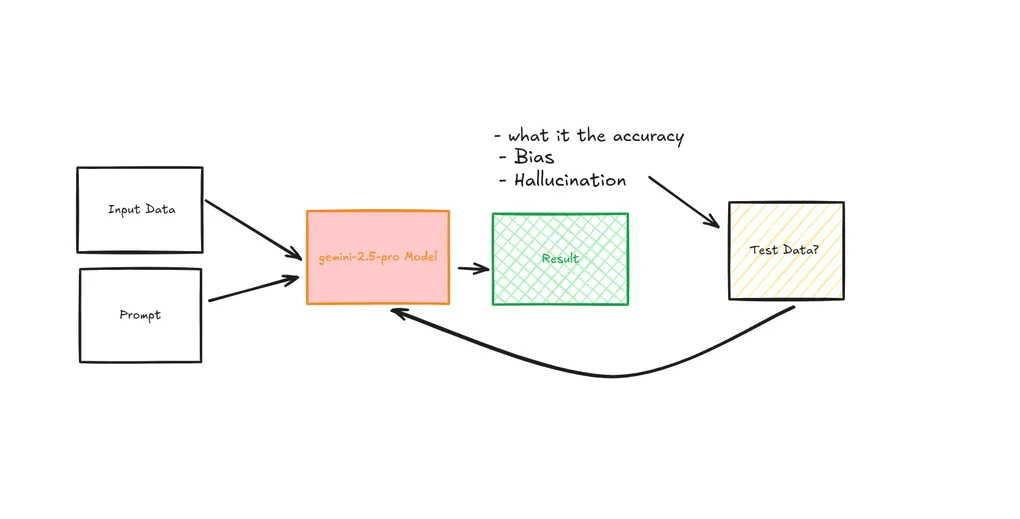
Overview ^1
LLM Evaluation needs to tap on:
- Accuracy
- Hallucination
- Bias
LLM Evaluation Frameworks
- BLEU - Scores For Translation Quality
- Perplexity - For Language Modeling
- Human evaluation with inter-annotator agreement Adversarial testing (Red Teaming)
- Domain Specific Benchmarks
LLM Evaluation Process
- Define Success criteria Before Deployment
- Create diverse test sets (not just happy paths)
- Measure consistently across model versions
- Track performance over time (models drift)
Types of LLM Evals Metrics ^4
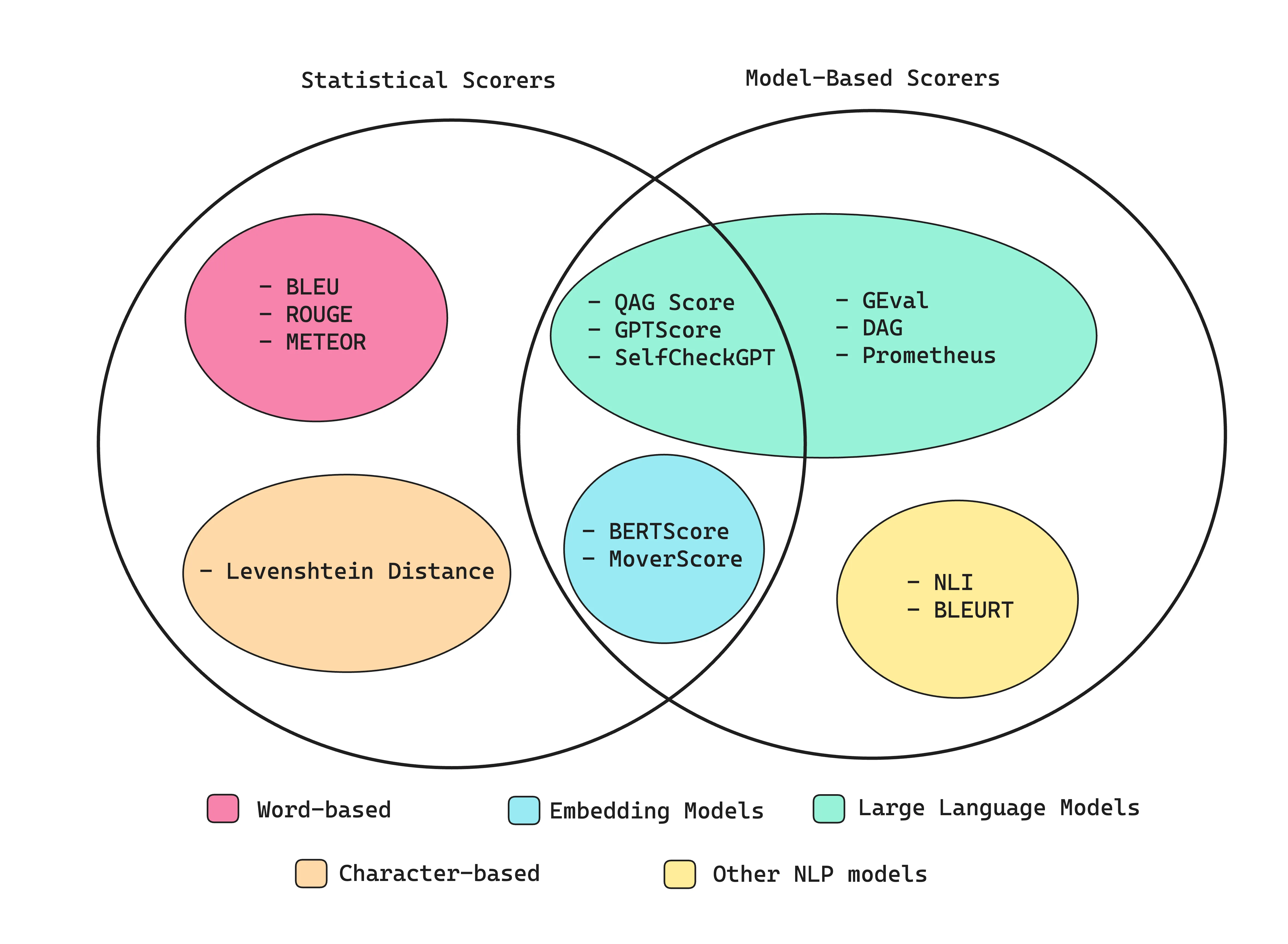
BLUE - Bilingual Evaluation Understudy ^2
BLUE is an algorithm that evaluates the quality of text which has been machine-translated from one natural language to another. The Quality is considered the difference between the machine translated against human translated.
The closer a machine translation is to a professional human translation, the better it is.
The evaluation does not account for intelligibility nor grammatical correctness.
BLEU and BLEU-derived metrics are most often used for machine translation.
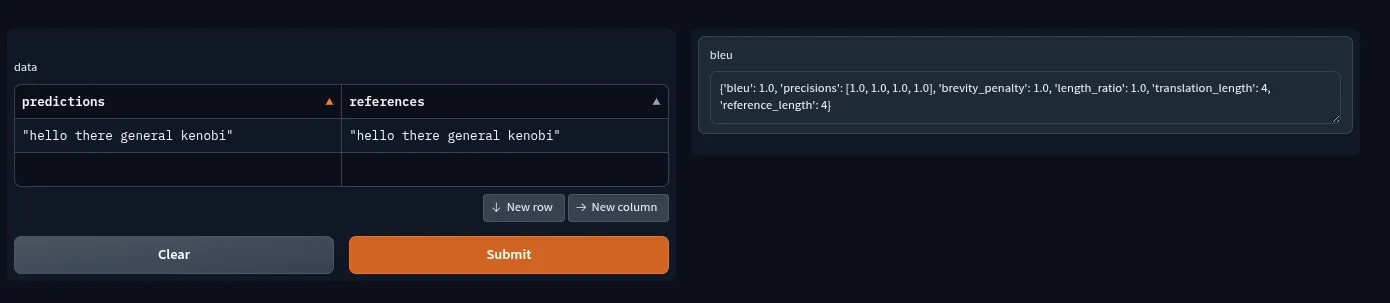
{
"bleu": 1,
"precisions": [
1,
1,
1,
1
],
"brevity_penalty": 1,
"length_ratio": 1,
"translation_length": 4,
"reference_length": 4
}In this example, we see the blue score is 1.0 meaning, completely matches the machine translation (the “predictions”) and reference (the “human translation value”).
For Hindi to English translation.
Input: रोज बोले जाने वाले अंग्रेजी वाक्य
Google Translate: daily spoken english sentences
My Initial translation: daily spoken english words
We might think this is fairly good translation? but its comely wrong, the Bleu score for this translation is literally 0.0.
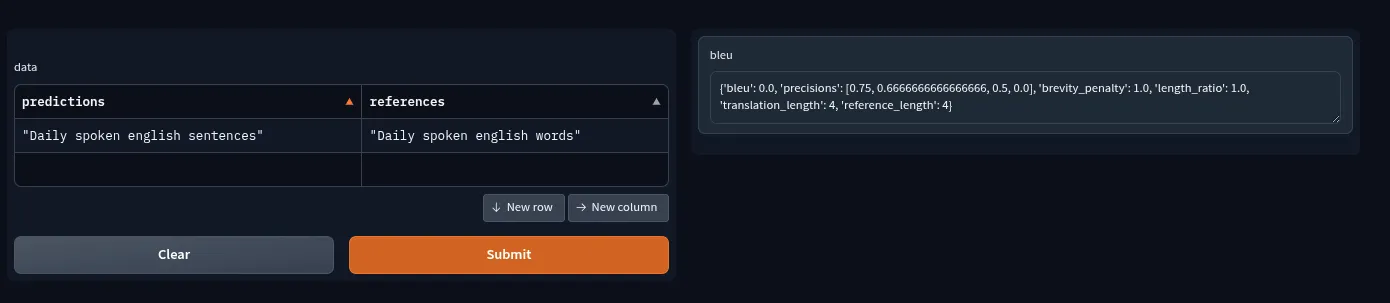
Since the almost all the words are same, but one word which make completely changes the meaning is sentences → words. Learn more details about this result here.
Trying Bleu is at https://huggingface.co/spaces/evaluate-metric/bleu
Perplexity - Natural Language Processing Evaluation. ^10
Perplexity is a key metric in natural language processing (NLP) that measures the quality of a language model.
It evaluates how well a probabilistic model predicts a sample, particularly focusing on the sequence of words in a text.
Perplexity is a measurement of uncertainty in the predictions of a language model. In simpler terms, it indicates how surprised a model is by the actual outcomes. The lower the perplexity, the better the model at predicting the next word in a sequence, reflecting higher confidence in its predictions.
The Perplexity (PP) of a Probabilistic Model (P) is given by,
This formula means that perplexity is the exponential of the average negative log-likelihood of the words in the sequence, given their previous context.
Perplexity of a Model can be >=1 when Perplexity is 1 which means, there is no uncertainty in the model predicting next word. When Perplexity is > 1 then that means there is uncertainty, for example Perplexity of a Model is 7 this means, in each prediction cycle, the model has 7 options it can choose.
The higher the perplexity, the less confident the model is in its predictions.
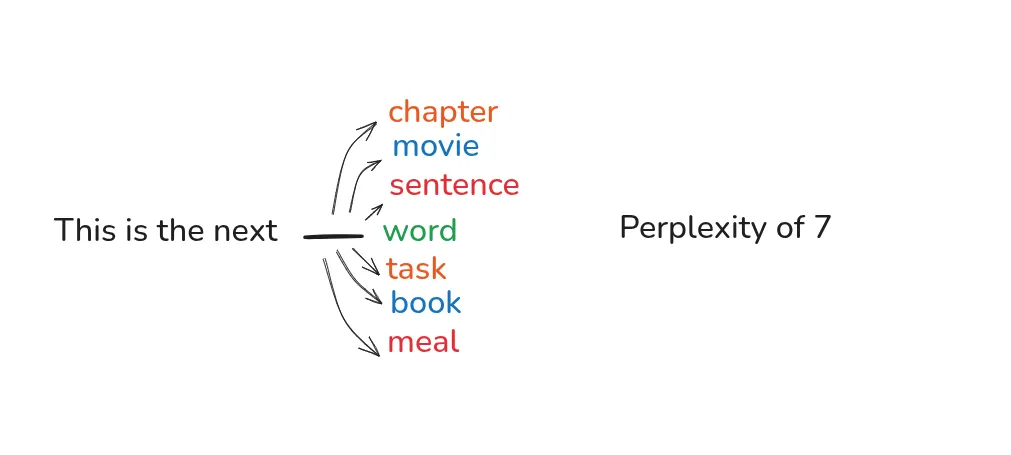
Calculating Perplexity (its interesting)
What is the Perplexity, i.e What’s the model’s predictions are on average as uncertain as choosing from {PP} possibilities.
Code / notebook for all these examples, are at 🧑💻 here.
🥬 Example 1
Given a sentence A triangle is a closed, two-dimensional geometric figure with three straight sides, three angles, and three vertices
The perplexity comes out to be 26.285186767578125. In essence, the models prediction are on average as uncertain as choosing from 26 different possibilities.
🥬 Example 2
For sentence I love learning, have a perplexity of 36641.0859375 , In essence the model prediction are on average as uncertain as choosing from 36641 different possibilities.
Its easy to summarize that for more predictable sequence of words, the Perplexity needs to be 1 or new 1, hence
🥬 Example 3
For sentence A B C D E F G H I J K L M N O P Q R S T U V W X Y Z the perplexity is 1.6623538732528687 , in essence, the model prediction are on average as uncertain as choosing from 1 different possibilities.
In simpler terms, it’s the product of the probability of each word given all the previous words in the sequence.
Conclusion
Perplexity is a critical metric in NLP for evaluating language models. It quantifies the model’s uncertainty in predicting the next word in a sequence, with lower values indicating better performance. By understanding and utilizing perplexity.
Human evaluation with inter-annotator agreement Adversarial testing (Red Teaming)
This is quite general approach, popularly derived from cybersecurity domain where evaluators deliberately try to make an LLM fail, behave unsafely, or produce harmful outputs. Things like, extracting system prompt, bypassing checks, Jail Breaking etc.
Purpose:
- Discover failure modes and edge cases
- Test safety guardrails and alignment
- Find ways users might jailbreak or misuse the model
- Identify biases, hallucinations, or harmful content generation
Sources:
[1] https://x.com/athleticKoder/status/1966849848688205843
[2] https://huggingface.co/spaces/evaluate-metric/bleu
[3] https://www.braintrust.dev/
[4] https://www.confident-ai.com/blog/llm-evaluation-metrics-everything-you-need-for-llm-evaluation
[5] https://github.com/openai/evals
[6] https://www.evidentlyai.com/llm-guide/llm-evaluation
[7] https://medium.com/@carolzhu/all-about-llm-evals-8a155a1235c7
[8] https://www.youtube.com/watch?v=89NuzmKokIk
[9] https://aclanthology.org/P02-1040/
[11] https://modal.com/notebooks/kunalsin9h/_/nb-NKxt2YhYxvM3mJPIeq1ZDC